Pyflame是uber开源的一个python性能profiler。
没有profile的优化就是耍流氓
说起python,被吐槽最多的就是慢。根据上面的名言,首先我们需要一个性能profiler。
profiler的两种原理
profile工具基本分成两种思路:
插桩
这个理解起来非常直白,在每个函数的开始和结束时计时,然后统计每个函数的执行时间。python自带的
Profile和cProfile模块就是这个原理。但是插桩会有两个问题,一是插桩计时本身带来的性能消耗overhead极大,二是对一个正在运行的程序没法插桩。采样
采样是注入正在运行的进程,高频地去探测函数调用栈。根据大数定理,探测到次数越多的函数运行时间越长。pyflame正是基于采样的原理。统计结果用另一个神器——火焰图flamegraph展示,我们就可以完整地了解cpu运行状态。
使用pyflame和火焰图
官方提供了pyflame源码,需要自己编译对应python版本,然后调用flamegraph生成火焰图svg。具体可以看官方文档。为了方便自己人使用,我写了个pyflame-server。
pyflame-server
https://github.com/Meteorix/pyflame-server
pyflame-server使用步骤很简单:
- 下载编译好的pyflame二进制文件(Linux x86_64),支持py2.6/2.7/3.4/3.5/3.6/3.7
- pyflame启动python进程,或者attach到正在运行的进程,得到profile.txt
- 上传profile.txt,查看火焰图页面
内部地址http://172.22.22.230:5000/
pyflame-server是基于flask简单的web项目,欢迎参与开发。
如何读图
- 横向是采样次数的占比,越长的span表示调用次数越多,即时间消耗越多
- 纵向是函数调用栈,从底向上,最下层是可执行文件的入口
- 每个span里面显示了文件路径、函数名、行号、采样次数等信息,可以自己缩放svg图看看。
以下面的代码为例:
1 | 1 import time |

从下往上看:
- 2/3的时间花在了第16行的
sum函数,1/3的时间是idle,即sleep的时候python释放了GIL。 sum函数第10行的for循环占用了一小段时间,第11行的add占用了大量时间- 再往上
add函数第5行只占用了一小段时间,说明大量时间被函数调用本身占用了
这样profile之后,如何进行优化就一目了然了吧。实际项目中,经过这样简单的profile,我们将一个NLP预处理的任务优化了70%的性能。
即时维护的分支
Uber写pyflame的哥们离职了,还没人接手这个项目。于是我自己维护了一个分支,做了几点微小的工作:
- 修复py2.7编译脚本
- 修复py3.7兼容性问题,感谢pr
- 修复anaconda的兼容性问题,感谢另一个pr
- 增加dockerfile,enable所有abi,目前同时支持py2.6/2.7/3.4-3.7
- 支持c/c++ profile,c/c++栈与python栈合并显示
How magic happens
Uber官方博客给了一篇由浅入深的讲解,这里简单提几个关键点。
ptrace
linux操作系统提供了一个强大的系统调用ptrace,让你可以注入任意进程(有sudo权限就是可以为所欲为)查看当前的寄存器、运行栈和内存,甚至可以任意修改别人的进程。
著名的gdb也是利用ptrace实现。比如打断点,其实就是保存了当前的运行状态,修改寄存器执行断点调试函数,之后恢复保存的运行状态继续运行。
PyThreadState
有了ptrace之后,我们可以通过python的符号找到PyThreadState,也就是python虚拟机保存线程状态(包括线程调用栈)的地方。然后通过PyThreadState,拿到虚拟机中的py调用栈,遍历栈帧反解出python的函数名、所在文件行号等信息。后面就是高频采样和输出统计结果了。
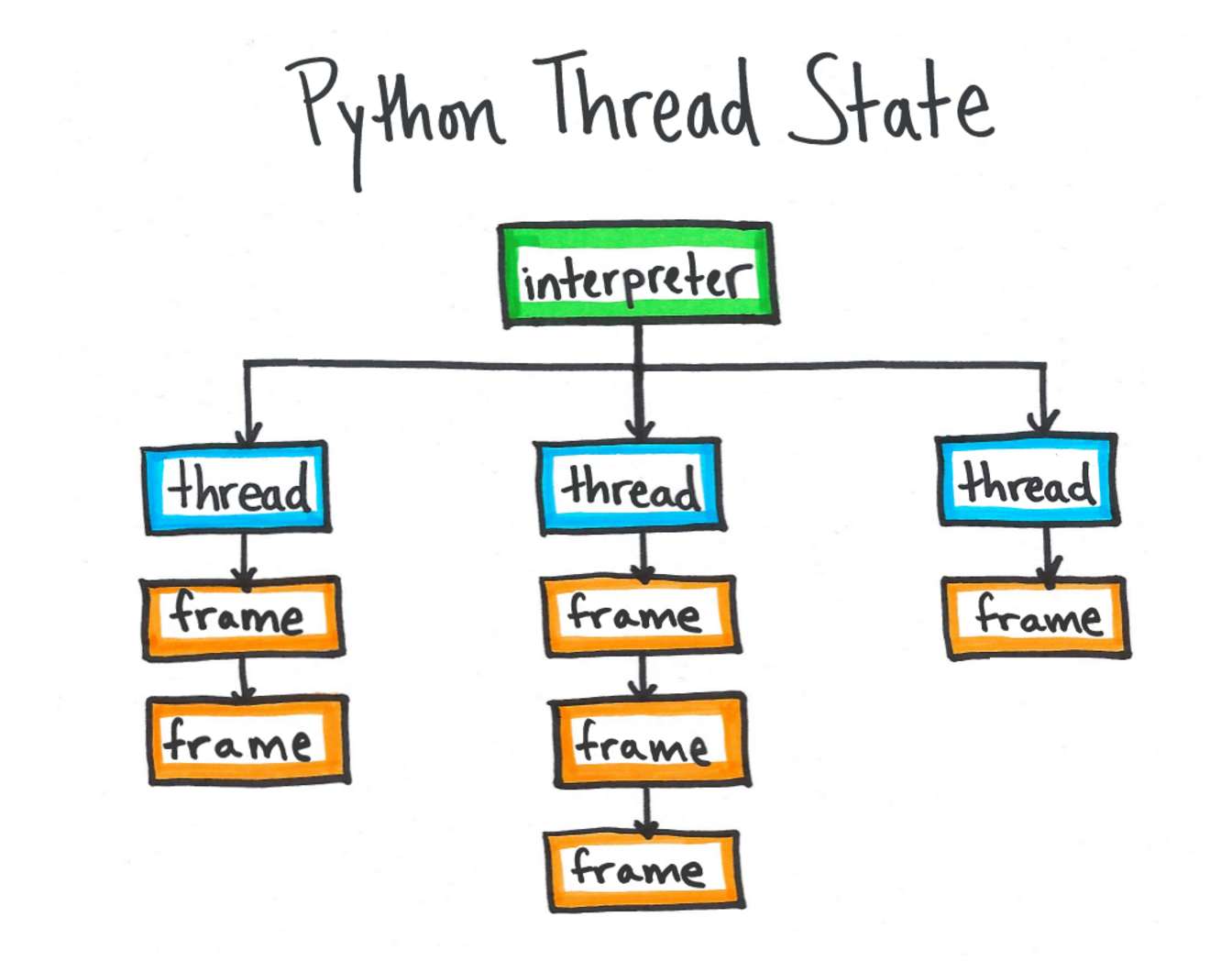
这部分如果想深入了解,可以看python虚拟机这篇介绍。
如果我们想profile c/c++呢
目前深度学习程序多半是c++和python混合开发。有时候我们看到python里面的一行代码,其实底层调用了几十行c++代码。这时候为了搞清楚性能消耗到底在哪,我们需要同时profile python和c++。这里提供基于pyflame和libunwind的实现思路。
libunwind
libunwind是另一个开源的c++库,同样利用ptrace实现了远程注入和解c栈的接口。于是我们可以在一次ptrace断点时,同时解出c栈和py栈,然后用一个巧妙的办法将两个栈merge到一起。再修改一下flamegraph的配色,可以得到c/c++栈和py栈混合profile的效果。

通过上面的火焰图,我们能清楚的看到每个python调用,实际上调用的底层c++函数。
另一个好处是,python没有占用GIL的时候,我们可以看到c++的调用栈。
to be continued…