BERT Runtime
最近继续怼BERT,项目大部分模型都上了BERT,真香啊。
本来一直在使用PyTorch JIT来解决加速和部署的问题,顺手还写了个service-streamer来做web和模型的中间件。
正好上个月NVIDIA开源了基于TensorRT的BERT代码,官方blog号称单次inference只用2.2ms,比cpu快20倍。但是正确的问法是:这东西能比TF/PyTorch快多少呢?
于是从TensorRT开始,认真学习了一波NVIDIA的BERT实现。并做了性能Benchmark对比TensorFlow和PyTorch,结论是gpu时间能快15%-30%。主要归因于对BERT的计算图优化,自己实现了4个cuda kernel,另外避免了TensorFlow和PyTorch等框架带来的overhead。
Prerequisite
比较有用的几个背景知识:
- 当然是BERT的Paper,Tensorflow实现,PyTorch实现
- Harvard写的著名解读The Annotated Transformer
- GPU和Cuda基础知识,很简单可以参考我的cuda101
TensorRT
TensorRT是NVIDIA官方推出的inference引擎,建立在CUDA之上。可以对TensorFlow/PyTorch等框架训练出来的模型进行CUDA优化,达到更高的inference性能。同时支持低精度参数、跨平台部署等,总之就是对自己家的GPU使用的最好。
跟TensorRT的编译斗争了一两天,整体还是比较顺畅,照着README:
- 准备环境,常规c++/py编译环境和cuda环境,我是
Titan XP + cuda-10.0 + cuDNN-7.4 - 下载TensorRT的binary release。TensorRT本身并没有开源,而是提供了编译好的lib。开源的周边代码包括:
include头文件plugin实现一些cuda扩展parser实现不同格式模型文件的解析
- Docker build编译用的镜像。
- 在Docker容器里面编译TensorRT的lib和开源代码。
TensorRT BERT
TensorRT的BERT实现代码在demo/BERT目录下,主要提供了:
- 针对BERT进行了4个计算图优化,用cuda实现了几个fusion的kernel,封装成TensorRT的plugin
- TensorFlow模型文件转TensorRT模型文件的脚本
- C++和python版API和完整的BERT inference代码。
还是看README,以SQuAD(QA)模型为例提供了完整的使用步骤:
- 下载BERT在SQuAD上finetune的TF模型文件,或者你也可以用自己finetune的模型文件
- 使用转换脚本将TF模型文件转换成TensorRT模型文件
- 使用另一个脚本将模型、参数、输入问题转换为Tensor形式的输入输出
- 编译C++可执行文件,即可测试加速后的模型和输入输出,并保存为
bert.engine
这个bert.engine文件,就可以单独使用了。既可以用C++ API或Python API加载后使用,也可以使用TensorRT Serving的docker直接加载做service。
Python API
NVIDIA也提供了Python API来完成上面的几个步骤,需要多编译一些python binding。不过既然我都编好了C++版本,就只用Python API做inference。后面测试结果可以看出,Python API在模型inference的性能上与C++版本比几乎没有损耗。
Python API的使用依赖pycuda,这是另一个官方库,用来做Python与CUDA之间的直接交互。这里包括分配显存、内存与显存之间copy tensor等。读取bert.engine执行inference则是使用TensorRT发布的whl包。
复现NVIDIA提供的性能数据
NVIDIA官方数据是在batchsize=1,seqlen=128时测试的。在我们的Titan XP上分别使用C++和Python API,GPU时间都在2.6ms左右,基本复现了官方数据。
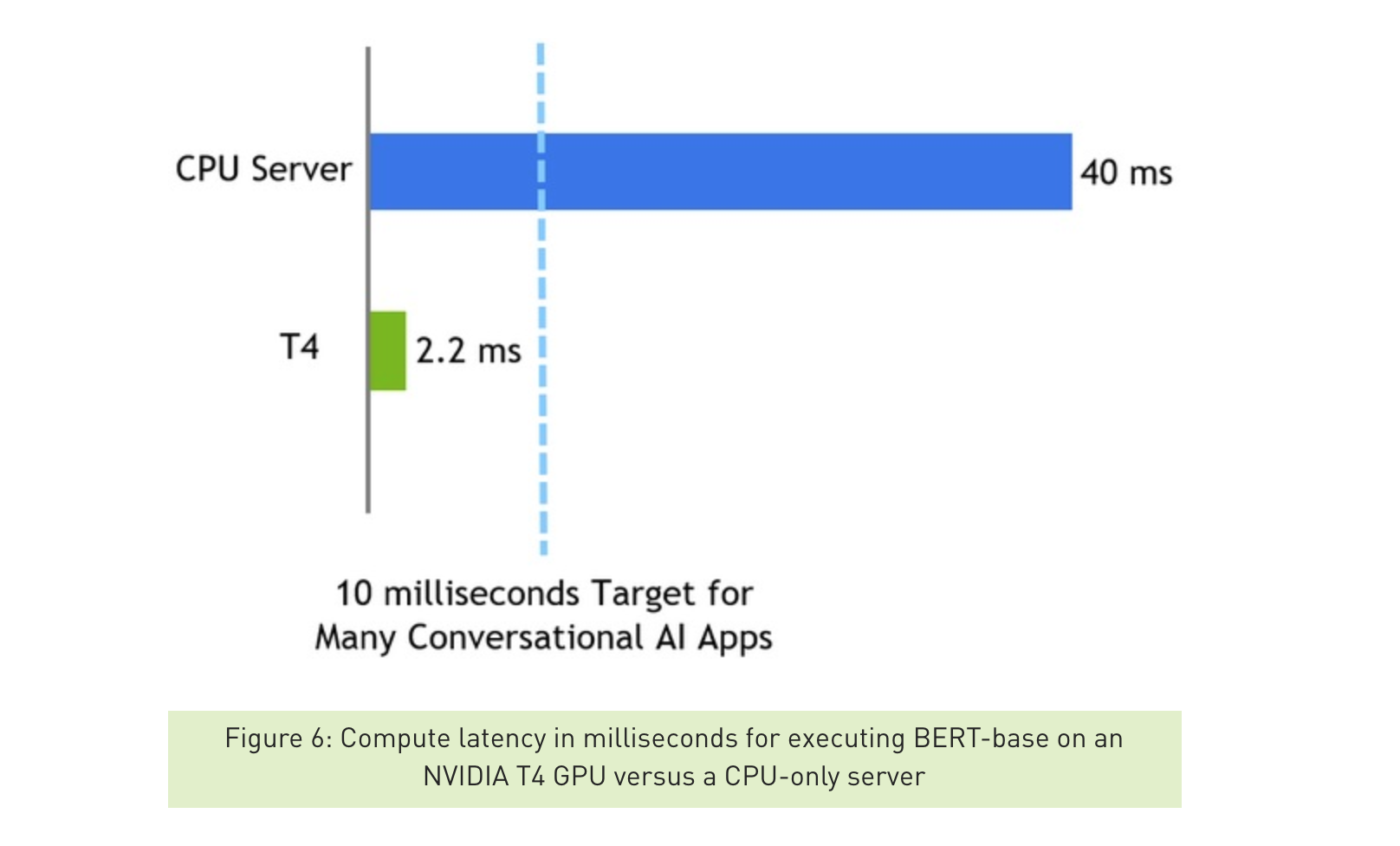
比较有意思的是,明明与pytorch和tensorflow等框架比更能说明bert优化的效果,可能是为了diss cpu好卖gpu卡吧 :P
下面我们就来正经做一下Benchmark
Benchmark
对于BERT的inference,很大一部分时间消耗在预处理上,即将输入的文字tokenize为index,执行padding和masking,再组装成tensor。而我们这里的benchmark只关心GPU执行inference的性能。所以我们的计时代码只包含GPU时间,也就是tensor输入到输出的时间,排除掉前后处理时间,另外包含tensor在CPU和GPU之间copy的时间。
环境
GPU版本
- GPU Titan XP
- Cuda 10.0
- Cudnn 7.5
Python3.6版本
- Torch==1.2.0
- TensorFlow==1.14.0
- tensorrt==5.1.5.0
BERT实现
- tensorrt基于 https://github.com/NVIDIA/TensorRT/tree/release/5.1/demo/BERT
- TensorFlow基于 https://github.com/google-research/bert
- PyTorch基于 https://github.com/huggingface/pytorch-transformers
模型
- bert-base 12层,SQuQA finetuned
- 相同的模型参数,分别转换为tensorrt/tf/pytorch模型文件
SQuAD任务
使用SQuAD(QA)任务进行测试1
2
3
4
5
6
7# 输入文章和问题
Passage: TensorRT is a high performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps.
Question: What is TensorRT?
# 输出答案
Answer: 'a high performance deep learning inference platform'
使用上面的QA任务样例,输入padding到Sequence Length=328,Batch Size分别使用1和32。测量100次取平均单句时间,单位是ms
结论
| bs * seqlen | tensorrt c++ | tensorrt py | tensorflow | pytorch | pytorch jit |
|---|---|---|---|---|---|
| 1 * 328 | 9.9 | 9.9 | 17 | 16.3 | 14.8 |
| 32 * 328 | 7.3 | 11.6 | 9.9 | 8.6 |
注:
- TensorFlow接口封装不太熟悉,仅供参考,目测与PyTorch无jit版本性能差不多
- TensorRT py接口暂时没实现多batch的inference,目测与c++版本性能差不多
- 所有测试GPU利用率都接近
100%,说明没有什么GPU之外的阻塞代码
结论:
- TensorRT比PyTorch快39%-26%
- TensorRT比PyTorch jit快33%-16%
计算图优化和kernel优化
那么我们来看看TensorRT实现的BERT,到底做了哪些优化。
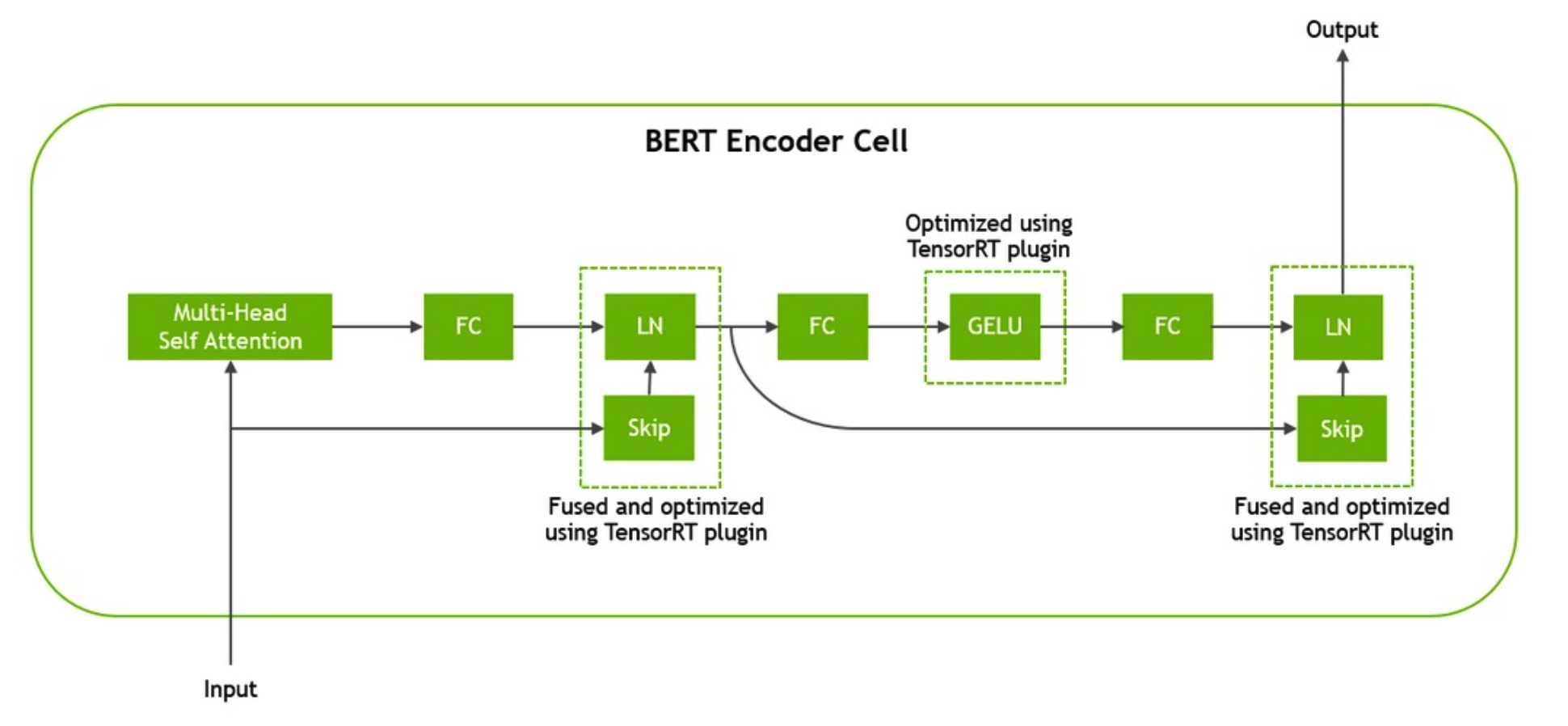
上面的计算图给了一个BERT Transformer Encoder的总览。对Transformer还不熟悉的话,可以回头看看Harvard写的著名解读The Annotated Transformer。总共有4点计算图优化,3点在Transformer中:
gelu激活函数的kernel实现skip和layernorm函数的fusionQ/K/V三个矩阵的合并乘法和转置
上面的前3个优化在12层Transformer中都会用到,所以性价比很高。第4点优化在最底层BERT Embedding层:
embedding和layernorm的fusion
下面分别看看4处优化是如何实现的,我也是趁此机会了解计算图优化和cuda kernel函数的编写。
Gelu
按照gelu的公式,如果每步分开计算,每步kernel调用都会进行一次global显存的读写。
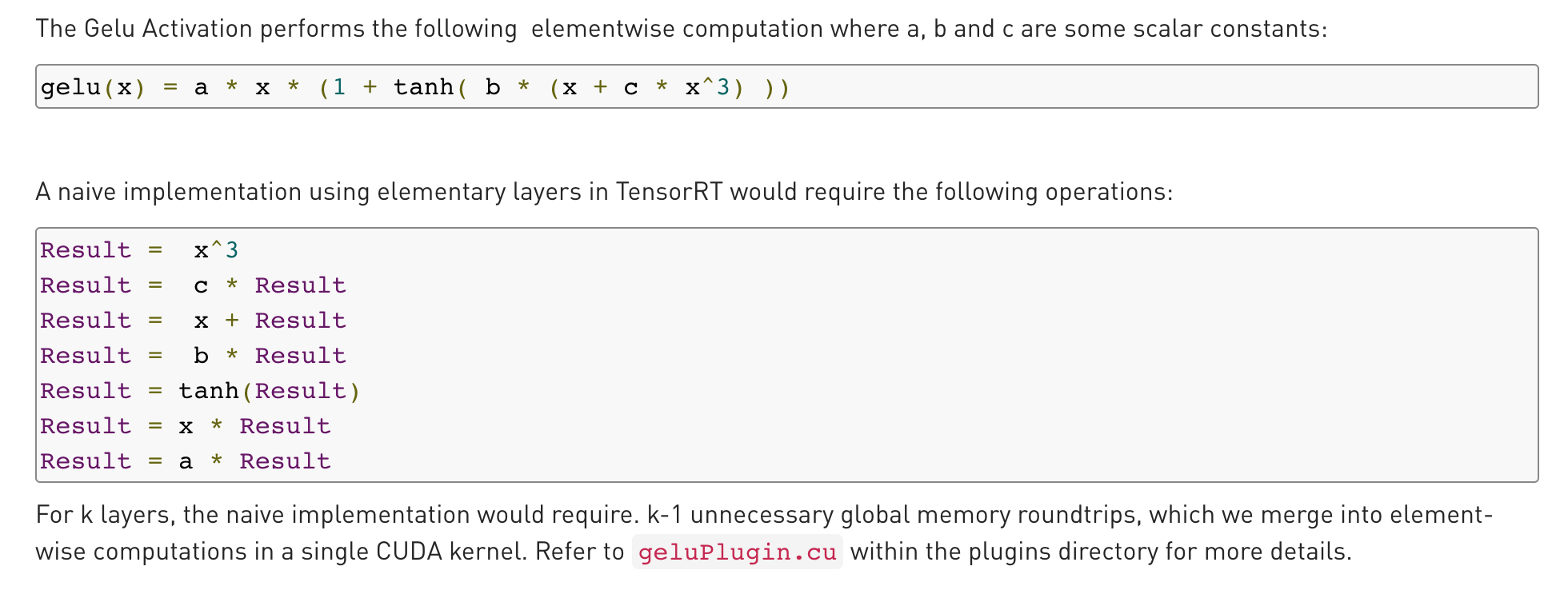
由于gpu的硬件特性,
global memory的访问速度非常慢(相对计算而言),这里可以参考前一篇笔记中的gpu设计和内存结构。
于是TensorRT就写一个gelu的kernel,一次kernel函数调用解决问题,只用一次显存读写。
https://github.com/NVIDIA/TensorRT/blob/release/5.1/demo/BERT/plugins/geluPlugin.cu
1 | // constants for approximating the normal cdf |
对比PyTorch JIT
1 | @torch.jit.script |
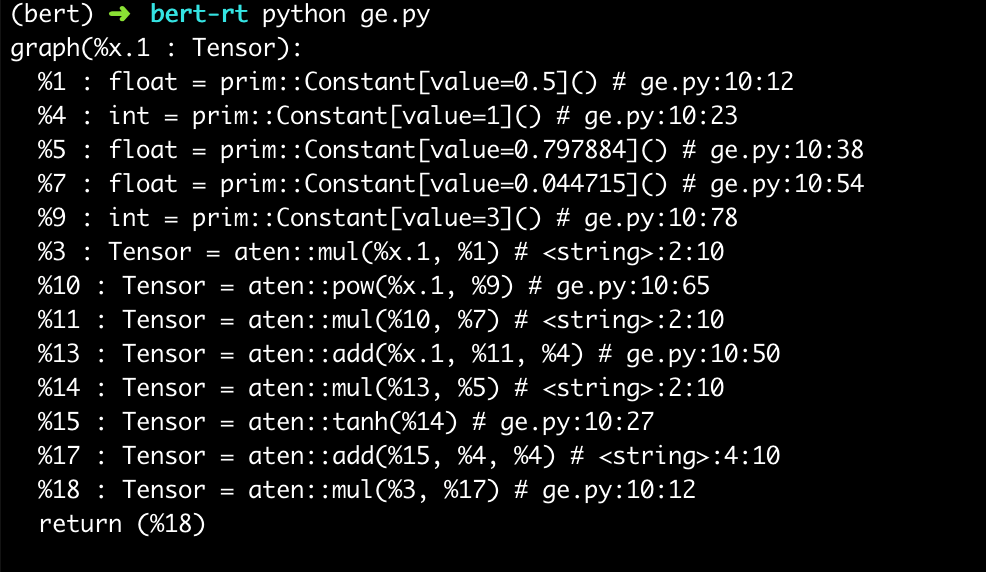
从计算图上看确实每一步是单独计算,除了tanh这种内置的函数,其他都要一层层函数调用。
不过,在PyTorch 1.2的最新代码中,我发现gelu也是用了内置的cuda实现,两者几乎等价。
Skip and Layer-Normalization
LayerNorm层的PyTorch实现1
2
3
4
5
6
7
8
9
10
11
12class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
忽略掉几个不重要的参数,主要是计算mean和std,各需要遍历一次所有输入参数。
加上LayerNorm之前的Skip层,一共需要遍历三次所有输入参数。
1 | x = LayerNorm(x + Sublayer(x)) |
根据上面说的GPU硬件和显存特性,启动三次kernel函数、遍历三次,都是消耗较大的。
所以优化为:
- 算
Skip层的同时计算x和x^2的平均值 再算
LayerNorm层时直接用x和x^2的平均值得到mean和std1
std = sqrt(mean(x^2) - mean(x)^2)
看代码的时候没明白,跟yuxian手推了一波这个公式(逃
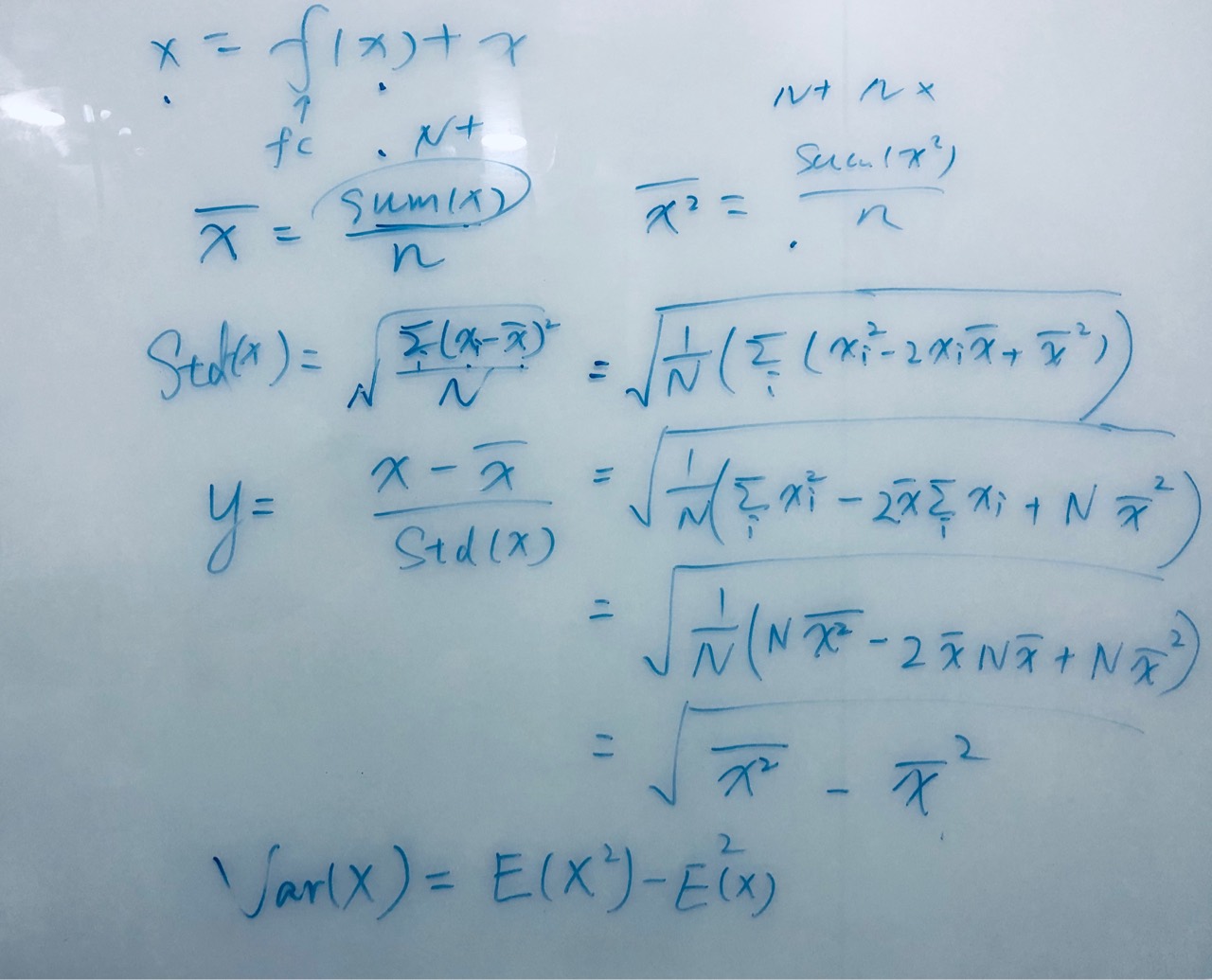
这样将三次遍历fusion成一次,省去了读写global显存的时间
cuda代码实现:
https://github.com/NVIDIA/TensorRT/blob/release/5.1/demo/BERT/plugins/skipLayerNormPlugin.cu
类似的还有Embeding+LN的fusion,理论上所有LN前面有一次遍历的都可以先算出来x和x^2的均值,省去两次遍历:
https://github.com/NVIDIA/TensorRT/blob/release/5.1/demo/BERT/plugins/embLayerNormPlugin.cu
QKV 优化
有了上面的基础,这里的两个优化比较容易理解,直接看图和代码
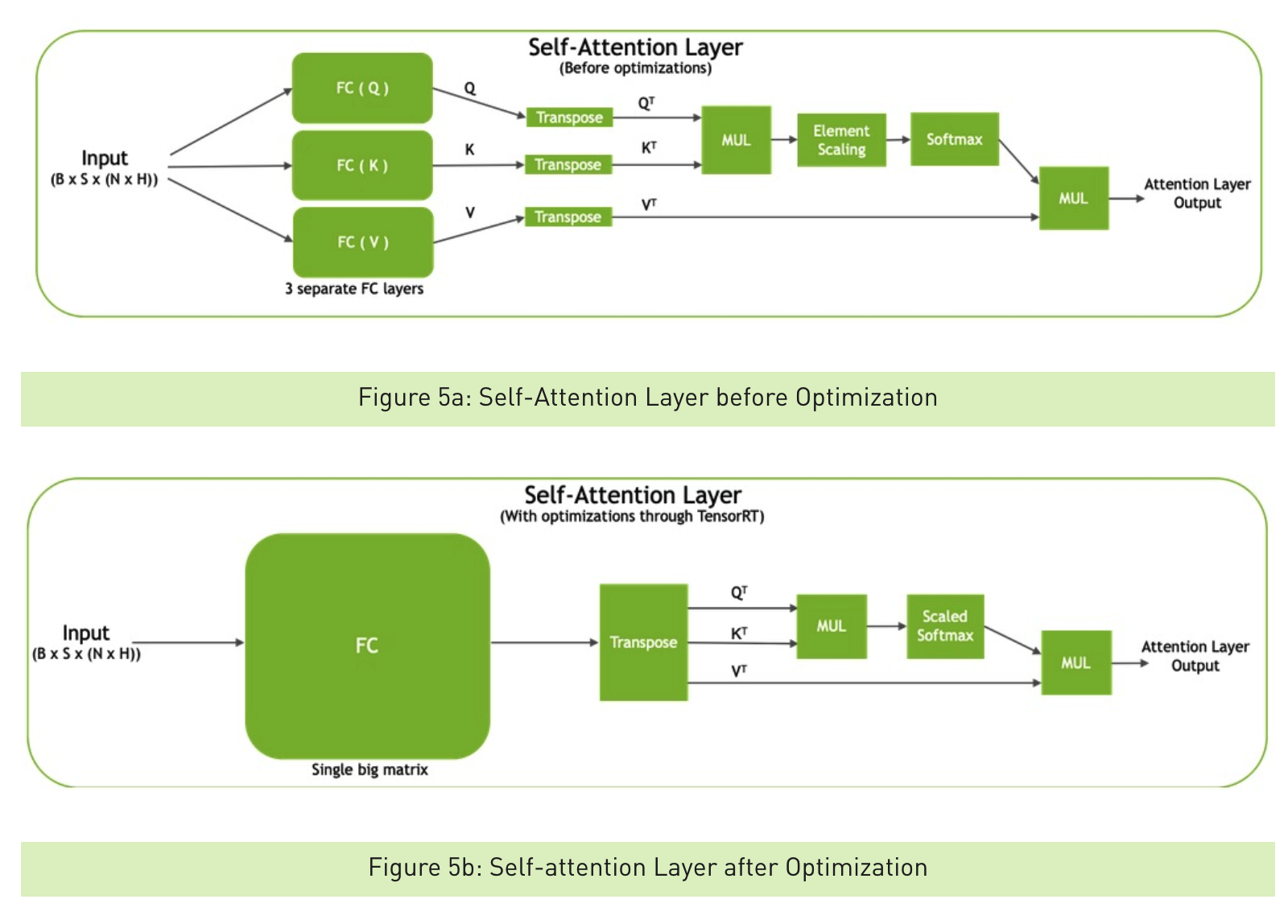
1)QKV本来是分别成三个矩阵然后转置,现在变成成一个三倍大的矩阵转置,再slice
https://github.com/NVIDIA/TensorRT/blob/release/5.1/demo/BERT/plugins/qkvToContextPlugin.cu
2)Scale+Softmax,在scale那一次遍历同时求得exp(x),减少一次遍历
异步执行
TensorRT的blog特别提了一下异步执行。由于CPU和GPU是异构的,在CPU和GPU之间copy tensor、GPU runtime执行计算都是异步完成的。不强制同步可以增加整个流程的吞吐量througput。Profile的时候需要特别注意这个异步的时间。这点在TensorRT的python代码中也能看到,实现的非常仔细。
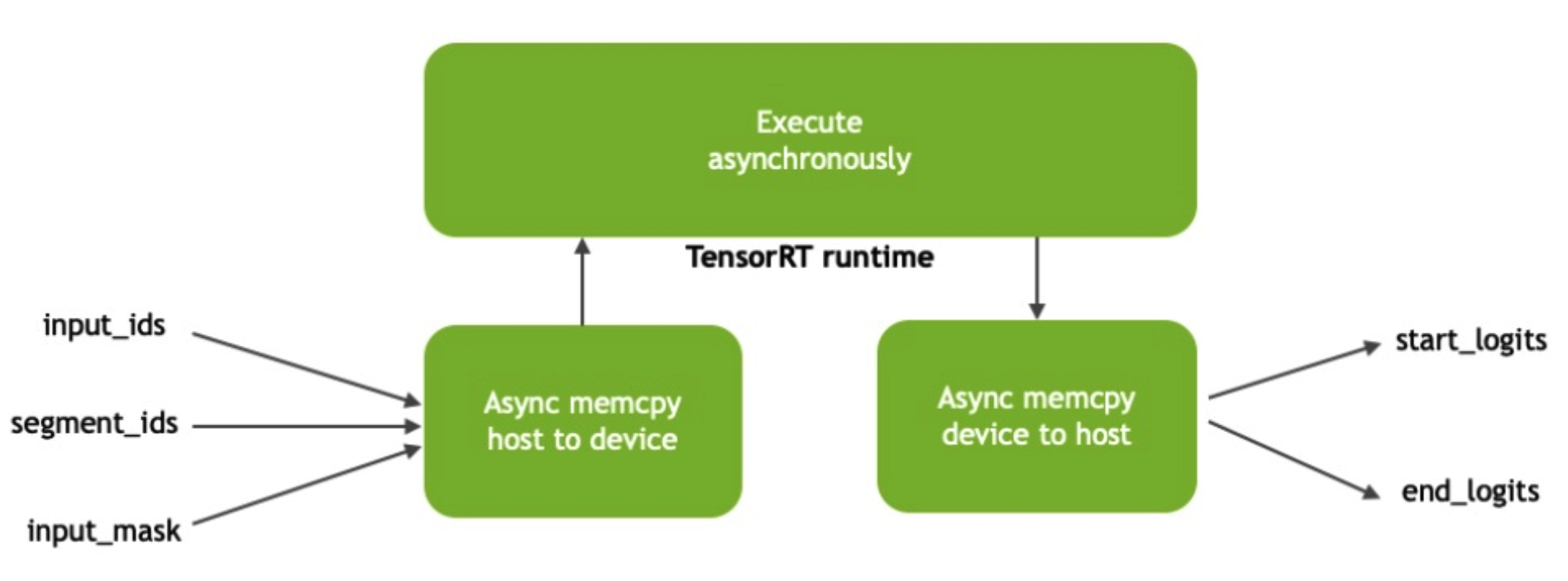
PyTorch实际上也是异步的,所以这点TensorRT没什么优势
如何使用
分析完TensorRT的BERT优化,我们看看能怎么用起来。
这30%左右的inference速度提升还是很香的,可能的用法有:
- 使用Python API,替换tf/pytorch的BERT实现,前后处理代码不用动
- 使用C++ API,封装前后处理C++代码,编译成二进制发布
- 直接使用tensorrt-inference-server,server只处理tensor,前后处理需要另外实现
这三种用法都需要将tf/pytorch训练(finetune)好的模型文件,转化为tensorrt的.engine文件:
- 转换模型参数,每个任务的模型BERT最上层会稍有不同
- 确定输入输出、batch_size等参数,生成tensor文件
- 用前两部的结果生成
.engine文件
So, what’s next?
根据项目的发展的阶段,考虑采用三种用法,主要先理顺模型迭代--业务开发--部署的流程。
再次感叹BERT真香,NLP领域幸好有BERT,才能搞这些优化。