cuda 101
最近开始做深度学习后端和性能优化,做到模型部分需要补补gpu和cuda知识。记录此篇入门笔记,配合官方文档食用。
NVIDIA的官方文档和blog写的真好,读了一天非常舒服。很多之前调包(Pytorch/Tensorflow)不理解的地方,都有更深的认识,期待尽早开始写自己的kernel。
get started
从这篇官方博客开始quickstart,写的非常好,可以快速了解gpu特性、编程模型、显存等
https://devblogs.nvidia.com/even-easier-introduction-cuda/
线程结构
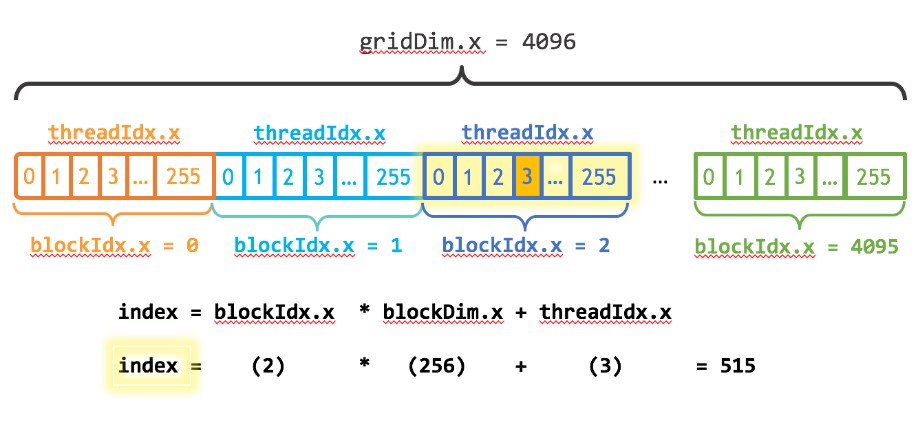
gpu上每个kernel函数调用,会包括
1 | 1 * grid --- n * block --- m * thread |
1 | // blockdim == m |
blockdim和griddim可以是1/2/3维的,方便不同维度的矩阵运算
内存分配
1 | int N = 1<<20; |
分配虚拟的共享内存,cpu和gpu都能访问
nvprof
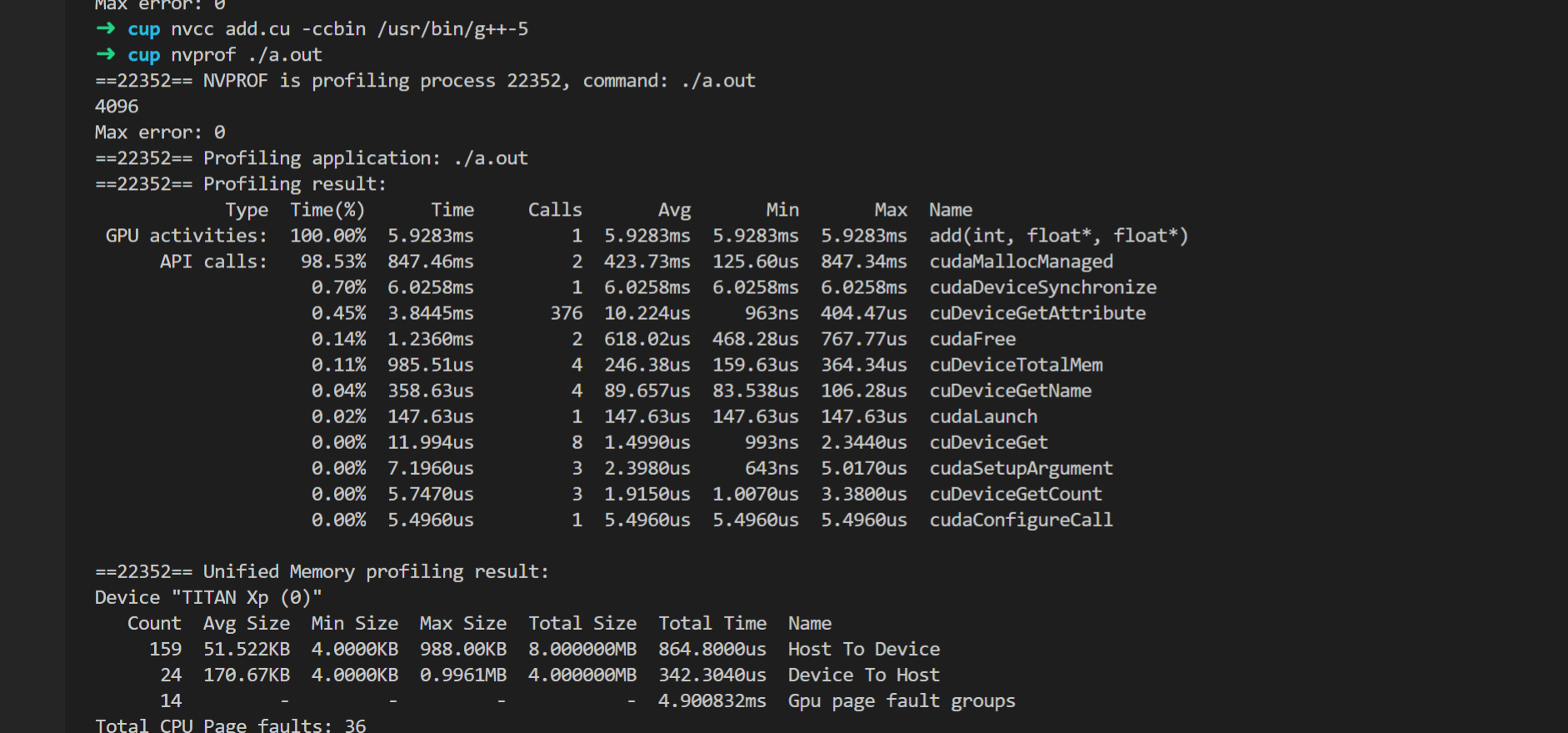
从上往下可以看出:
- kernel function调用(gpu device)
- cuda c runtime调用(cpu host)
- 显存/内存migration调用
这个感觉会很有用,可以认真profile一下pytorch程序
两种显存-内存分配方式
在我的titan xp卡上,nvprof出来的结果不对,加了很多block并行并没有加速kernel function。上面的博客非常贴心的提示了这个问题,引出下面的博客:
https://devblogs.nvidia.com/unified-memory-cuda-beginners/
原来是两种不同的共享内存分享方式
- 旧的(kapler),先分配到gpu,cpu访问时引起page fault,再从gpu读取
- 新的(pascal),先分配到cpu,gpu访问时引起page fault,再从cpu读取
新的好处:
- gpu物理显存不用占太多,按需取
- 多gpu可以共享虚拟内存表(似乎是这个意思)
注意: profile的时候,第一次会算上migration内存的时间,可以先prefetch解决这个问题
bandwidth
1 | bandwidth = bytes / seconds |
显存的上限在500GB/s这个数量级
下面开始进入正经的cuda c编程指南
https://docs.nvidia.com/cuda/cuda-c-programming-guide/
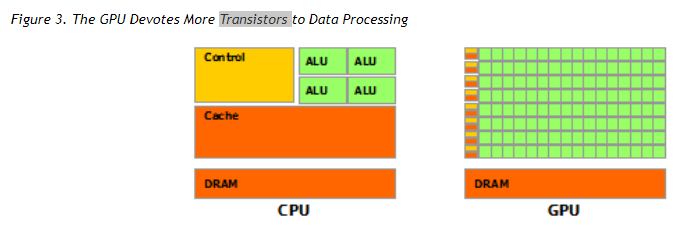
gpu设计
摩尔定律限制了芯片上的晶体管数量
- cpu芯片的晶体管大部分用在了control、cache(L1/L2/L3)、少量 的alu
- gpu芯片则绝大部分用在了alu,少量control和cache
这使得gpu计算(GFLOPS)和memory access能力大了好多个数量级。适合大量data并行计算,少control flow
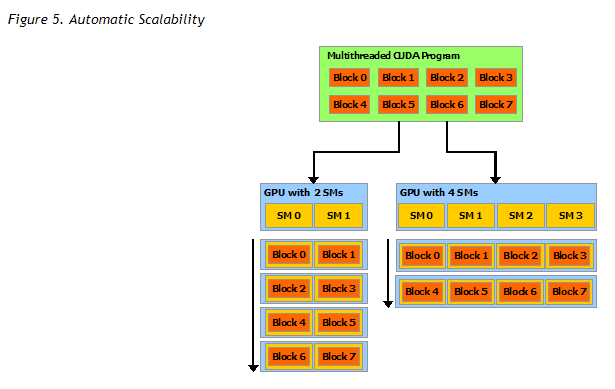
自动多核并行
每个核(SM)按block分配,自动占满所有SM
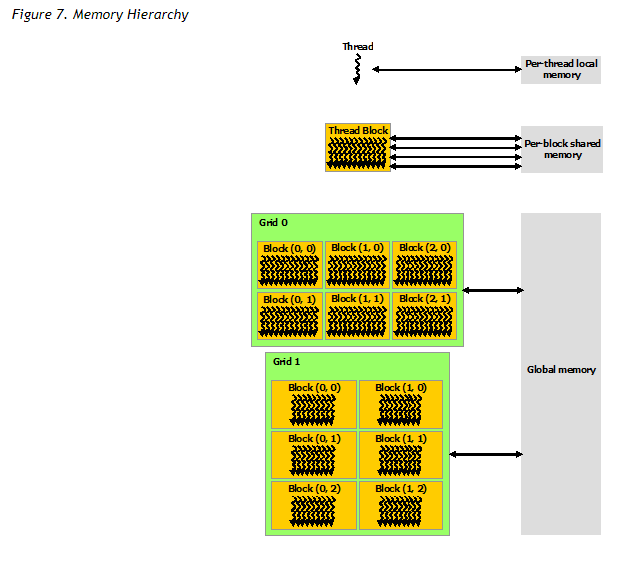
内存结构
- 线程内本地内存
- block内共享内存——block里面的thread间共享
- global内存——block间和grid间共享
Unified Memory
cpu和gpu实际上是异构编程,执行运算是异步的,分配内存也是在不同的物理设备
unified memory是将两块内存伪装成同一份managed memory,大大减小了编程难度
nvcc编译
离线编译
- 分离device代码和host代码
- device代码编译成汇编(ptx)或者二进制
- host代码替换<<<…>>>成cuda c runtime函数,然后由nvcc调用gcc/g++等编译器编译
jit编译
- ptx代码,可以在runtime进一步被编译成device二进制代码,这就是jit
- 好处是在保证ptx兼容性的情况下,旧的程序可以享受新的硬件
- jit编译之后,第一次会生成一个cache,driver更新会cache会失效
兼容性
- 二进制兼容性
- ptx兼容性
- 应用兼容性
- c/c++兼容性 device代码只支持c++子集
- 64bit兼容性
主要是一些编译选项,用的时候查文档吧
CUDA C Runtime
cudart library 静态链接库、动态链接库都有提供
初始化
- cuda代码第一次运行的时候,会隐式初始化。profile的时候注意忽略这个时间。
- 每个device初始化一个CUDA context,进程内所有线程共享这些context,然后jit编译pxt代码,load进显存。
- host可以通过cudaSetDevice(1) 指定运行的context,即指定运行的gpu卡
- 进程可以cudaDeviceReset()手动销毁这个context
设备显存
显存可以是linear memory或者cuda arrays
cuda arrays好像是用于texture(游戏引擎的texture?后面再研究这个)
linear memory就是正经的40bit地址了,可以用指针指向
1 | cudaMalloc() |
要注意分配2d/3d内存的时候,index和stride方式稍有变化,指针别用错了
1 | // 各种memcpy全局显存的方式 |
共享显存 shared memory
注意区分unified memory,这里是说同一block中thread shared memory
shared memory比global memory快很多,相当于cpu的L1 cache?
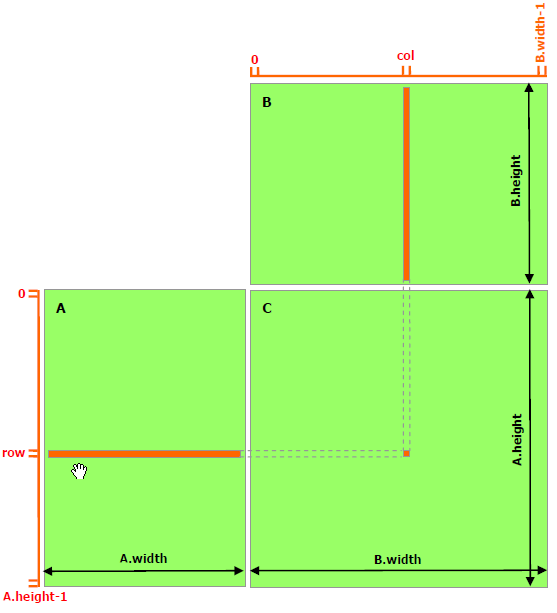
下面利用shared memory实现更快的矩阵乘法,这个例子太经典了,链接在这里经常复习下
没有使用shared memory时,需要访问A.width*B.height次global memory
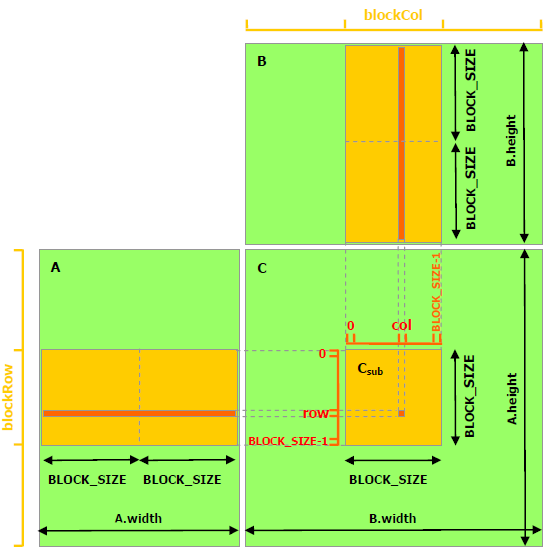
使用shared memory,将一个block的数据一次性读取到shared memory,访问global memory的次数降为(A.width/block_size)*(B.height/block_size)
page-locked host memory
有点像把host memory mmap到device memory,好处有:
- memcpy和kernel执行是并行的
- mapped到显存,甚至不用memcpy了
- bandwith更高
page-locked host memory是整个系统层面珍稀的资源,不要滥用。
有三种使用方式,具体用的时候再研究:
- portable
- write-combining
- mapped
异步执行
所有host计算、device计算、所有类型的memcpy之间都是异步的、可以并发的。
注意profile的时候,可以用CUDA_LAUNCH_BLOCKING环境变量disable掉异步。(以后要用好Nsight/Visual Profiler)
异步模型
目测有两种重要的异步编程模型:stream和graph
stream
stream有点像游戏引擎,开一个或者多个stream,host代码往stream中发计算指令,需要的时候synchronize。
1 | // 两个stream并行的例子 |
stream也支持callback,异步执行完之后callback host代码。注意callback不能再有cuda调用,否则会死锁。
graph
graph则是定义好所有计算指令作为node,计算顺序和依赖关系也定义好作为edge,定义好之后每一步触发执行
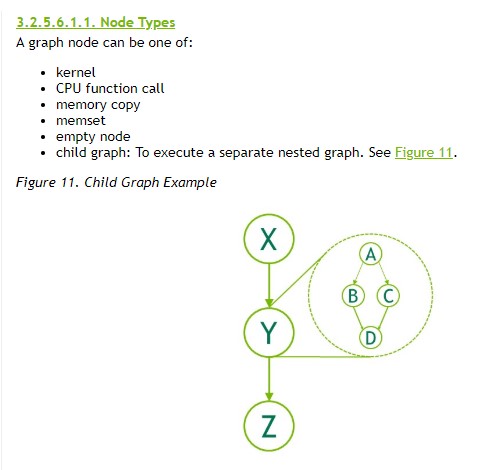
stream追求灵活、graph则是更适合复杂的计算关系和追求执行效率
Graph可以用两种方式定义:
- 录制stream
- 手动定义node和edge
event
多个stream之间,可以用event同步,类似1
2
3
4
5
6
7
8
9
10
11
event还能用于多stream录制成一个graph,wait event,相当于```thread.join()```吧。
还有个用途,可以用来异步计时。定义start和stop event,然后使用``cudaEventElaspedTime``
### 多卡
多卡切换
```cpp
cudaSetDevice(0);
cudaSetDevice(1);
stream和device是绑定的,可以用event来同步多卡之间的stream
64bit程序,可以通过api开启多卡之间的显存访问(目测多卡训练会有用?)
虚拟内存
64bit程序,host和device共用一个虚拟内存,可以参考上面的显存-内存分配方式
IPC
cuda也提供了IPC方式,多进程可以share显存指针和event
后面在研究吧。。。
error & callstack
cuda-gdb / Nsight
texture
后面再研究吧,应该是游戏引擎用的?或者黑科技加速?
还能跟opengl/dx接口交互。。。
性能指南
TODO….